Big Data ist in aller Munde und ich hab hin und wieder erwähnt, dass ich selbst an einem Forschungsprojekt (PDF) arbeite, bei dem ich den Absatz von Musikalben mithilfe von Twitter prognostizieren möchte. Die Erkenntnis: Es klappt – und zwar mit beeindruckender Genauigkeit.
Das Studiendesign ist im Prinzip simpel: Man schaut sich an, wie oft über ein Album getweetet wurde und vergleicht das mit den Verkaufszahlen. Wenn es eine starke Korrelation gibt, ist das Modell verlässlich.
Daten von Universal Music und DiscoverText
Für die Studie habe ich 25 Alben von Universal Music untersucht, die zwischen Ende Januar und Mitte Februar veröffentlicht wurden, unter anderem „Passione“ von Andrea Bocelli, „Two Lanes of Freedom“ von Tim McGraw oder „Chasing The Saturdays“ von The Saturdays. Die Verkaufszahlen für drei Wochen nach der Veröffentlichung wurden von der Universal Music Group in Santa Monica zur Verfügung gestellt.

Über DiscoverText, ein kostenpflichtiges Analyse-Tool, habe ich englischsprachige Tweets gesammelt, die entweder den Künstlernamen oder den Albumtitel enthielten und in einem Zeitraum von zwei Wochen vor Veröffentlichung bis eine Woche nach Veröffentlichung gepostet wurden.
3 Millionen Tweets für 2.500 Dollar
Grundsätzlich kann man Tweets auch über die Twitter-API sammeln, aber da ich in meinem Fall die Tweets rückwirkend betrachtet habe, mussten die eingekauft werden. Kostenpunkt: 2.500 Dollar für drei Millionen Tweets, die meine Alma Mater, die University of Southern California, bezahlt hat.
Nachdem ich die Daten gesammelt hatte, musste ich sie sinnvoll ordnen. Ich habe zwei grobe Modelle berücksichtigt: In dem ersten Modell waren alle Tweets, die entweder den Künstlernamen oder den Albumtitel enthielten, im zweiten Modell wurden Tweets berücksichtigt, die sowohl den Künstlernamen als auch den Albumtitel verwenden. Auch wurden hier Tweets gesammelt, in denen der Künstlername und Wörter wie „CD“, „Album“, „Release“ oder bestimmte Songtitel vorkamen.
In beiden Modellen habe ich pro Album eine Stichprobe der gesammelten Tweets auf ihre Relevanz überprüft, denn bei Alben wie „At Peace“ von Ballake Sissoko oder „Icon“ von der Allman Brothers Band haben die wenigsten Tweets etwas mit dem Album zu tun. Insgesamt hatte ich die Freude 18.000 Tweets zu lesen und zu kodieren – pro Tweet braucht man ca. zwei Sekunden.
Drei Modelle, 25 Alben und 23.500 gelesene Tweets
Da das Modell 1a relativ unbrauchbar ist, weil viele irrelevante Tweets gesammelt werden, wurde es nicht weiter berücksichtigt. Für die anderen drei Modelle (1b = relevante Tweets, Künstler oder Album; 2a = alle Tweets, Künstler und Album; 2b = relevante Tweets, Künstler und Album) wurde ermittelt, wie viel Tweets pro Tag von wie vielen unterschiedlichen Usern (Unique User) gesendet wurden und wie viele gemeinsamen Follower (Reichweite) die Unique User haben.
Bei einem Zeitraum von 22 Tagen kommt man somit auf 198 Variablen. Zusätzlich habe ich noch die Summen für die Wochen genommen (2 Wochen vor Veröffentlichung, 1 Woche vor Veröffentlichung, 1 Woche nach Veröffentlichung) und für die beiden Zeiträume vor und nach der Veröffentlichung das Sentiment analysiert, also sprich, ob der Tweet positiv, negativ oder neutral gefasst ist. Für die Sentiment-Analyse durfte ich mir noch einmal 5.500 Tweets durchlesen.
255 unabhängige Variablen und 288 lineare Regressionsmodelle
Insgesamt kam ich demnach auf 255 unabhängige Variablen sowie die drei Verkaufsvariablen. Bei 25 Alben macht das knapp 6.500 Datenpunkte, die mit linearen Regressionsmodellen mit der Statistiksoftware IBM SPSS 21 untersucht wurden. Insgesamt wurden 288 unterschiedliche Modelle berechnet, je nach dem, welche Daten man zugrunde legt.
Die Ergebnisse im Überblick: Die Reichweite ist die verlässlichste Datenquelle, Daten auf Tagesbasis sind deutlich besser als auf Wochenbasis, Modell 2a und 2b haben die besten Ergebnisse hervorgebracht und die Sentiment-Analyse ist unwichtig.
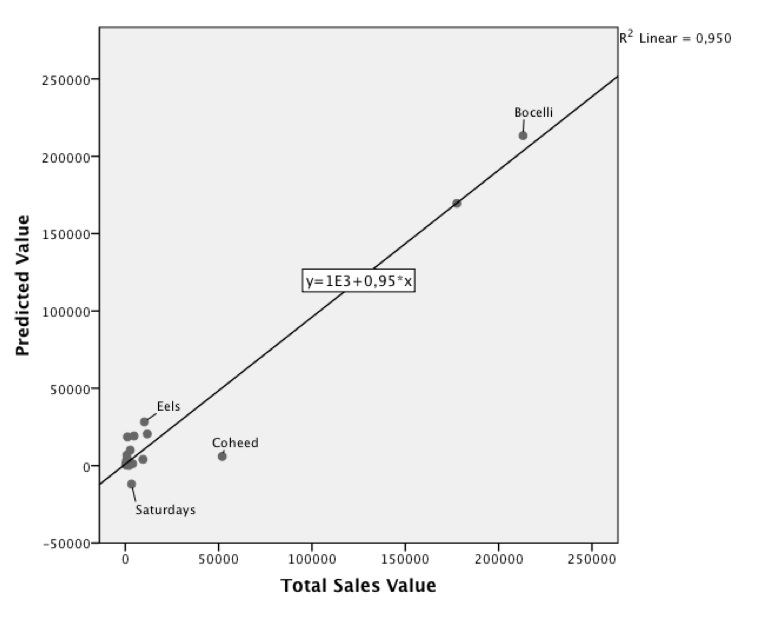
95-prozentige Genauigkeit
Beobachtet man die tägliche Reichweite der relevanten Tweets zwei Wochen vor Veröffentlichung eines Albums, die Künstlernamen und Albumtitel enthalten, kann man die Verkaufszahlen der nächsten drei Verkaufsperioden mit 95-prozentiger Genauigkeit prognostizieren.
Zugegeben: Ich war selbst von der Zuverlässigkeit überrascht. Ein Grund für die hohe Korrelation dürfte sein, dass ich im Gegensatz zu den meisten Studien nicht das Volumen der Tweets sondern die Reichweite betrachte.
Reichweiten-Analyse bringt Vorteile mit sich
Das hat zwei entscheidende Vorteile: Zum einen wird der Einfluss eines Twitter-Users berücksichtigt. Wenn Hans Meier und der „Rolling Stone“ ein Album empfehlen, sind das zwei Tweets von zwei Usern. Der „Rolling Stone“ hat aber deutlich mehr Follower, wird also auch einen größeren Einfluss auf die Verkaufszahlen haben.
Zum anderen umgeht man somit das Problem, dass es auf Twitter schätzungsweise 20 Millionen Fake-Accounts gibt. Auch ich habe in den Stichproben und den 23.500 Tweets, die ich manuell gelesen habe, Auffälligkeiten gesehen, wo der Verdacht nahe liegt, dass es sich um Fake-Profile handelt. Die haben aber eine zu vernachlässigende Reichweite und beeinflussen daher nicht das Ergebnis.
Modell hat Einschränkungen
Natürlich hat meine Studie auch Einschränkungen. Alben, die „Romance“oder „Best Of“ hießen habe ich von vornherein ausgeschlossen. Auch bei Bands die „The Saturdays“ heißen, hat das Modell Schwierigkeiten.
Das zweite Problem ist, dass mein Studienergebnis zwar interessant ist, aber aus Marketing-Sicht wenig nützlich, denn die Marketing-Ausgaben werden viel früher geplant.
Ursprünglich war geplant, dass ich das Twitter-Volumen rund um die Single-Auskopplungen beobachten wollte, doch aus verschiedenen Gründen konnte ich dieses Studiendesign nicht realisieren.
Das dritte Problem: Korrelation ist nicht Kausalität. Nur weil ein Marketing-Manager es schafft, dass viele User über ein Album tweeten, werden die Absatzzahlen vermutlich nicht steigen. Das muss man im Hinterkopf behalten.
Big Data-Analysen haben Potential
Soweit ich weiß ist das die erste Studie, die Musikverkäufe mithilfe von Twitter prognostiziert. Der Grundstein ist sozusagen gelegt und besonders die Erkenntnis, dass die Reichweite aussagekräftiger als andere Daten ist, kann meiner Meinung nach auch für andere Studien hilfreich sein.
Nichtsdestotrotz ist es wichtig, weiter zu forschen und zu schauen, ob man Modelle entwickeln kann, die auch tatsächlich bei der Marketing-Planung helfen können.
Dennoch: Ich bin nun auch aus eigener Erfahrung von dem Potential von Big Data-Analysen überzeugt!
Update:
Es gab ja ein paar Fragen, wie die beiden Alben mit den größten Verkaufszahlen (Bocelli und Tim McGraw) die Korrelation beeinflussen würden. Leser Stefan Hahmann von der TU Dresden hat auch noch mal mit einem anderen Programm nachgerechnet und ist auf eine ebenso hohe Korrelation gekommen. Werden die drei größten Outlier weggelassen, sinkt die Korrelation natürlich, ist aber immer noch nachweisbar. Da es sich bei meiner Studie aber nur um eine kleine Stichprobe handelt, vermute ich, dass die Outlier bei einer größeren Analyse normalisiert werden – bei meinem Fazit bleibe ich also: Es muss mehr geforscht werden. Vielen Dank noch mal an Stefan Hahmann.
Bild: Robert Vossen














